I was looking for a way, to get the candidate ID and Job Application ID for a given User. In a Process Trigger, you can get a good overview of an employee who moved from REC, via ONB to EC, and there I found all the required information.
Manage Data → Search → Process Trigger
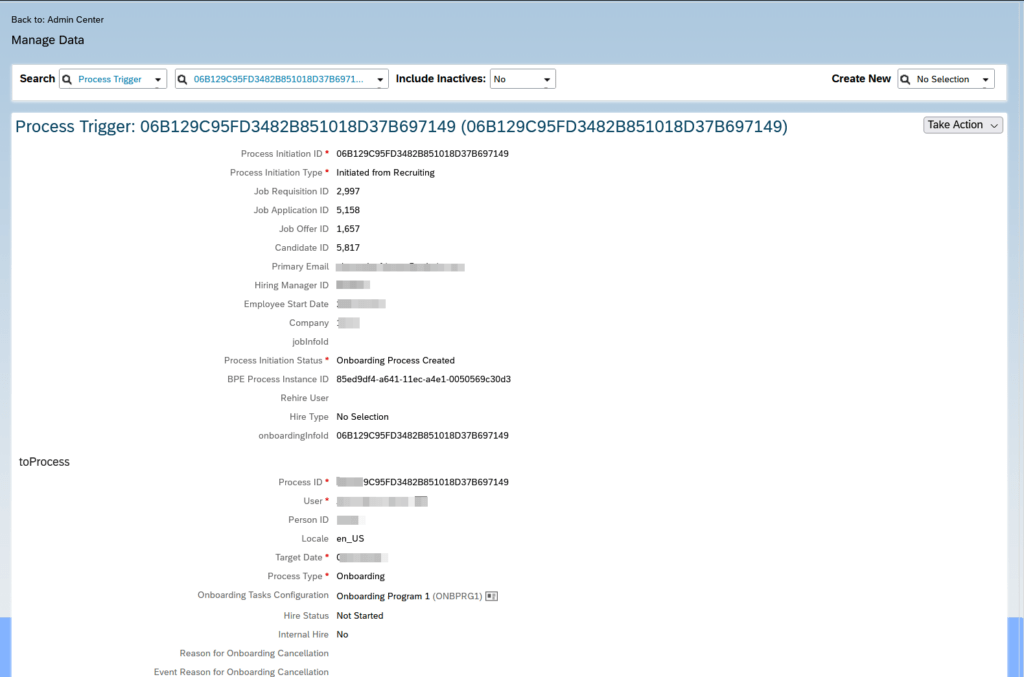
This information can also be fetched via API.
API Entity: ONB2Process
### Process Trigger
GET {{$dotenv sf_api_url}}/odata/v2/ONB2Process('06B129C95FD3482B851018D37B697149')
Authorization: Basic {{$dotenv sf_api_auth_base64}}
Accept: application/json
### processTriggerNav, includes rcmCandidateId, rcmApplicationId, rcmJobReqId
GET {{$dotenv sf_api_url}}/odata/v2/ONB2Process('06B129C95FD3482B851018D37B697149')
?$expand=processTriggerNav
Authorization: Basic {{$dotenv sf_api_auth_base64}}
Accept: application/json
### Fetch candidateId, jobApplicationId, jobReqId via userId
GET {{$dotenv sf_api_url}}/odata/v2/User(100000)/userOfONB2ProcessNav
?$expand=processTriggerNav
&$select=processId,processTriggerNav/rcmApplicationId,processTriggerNav/rcmJobReqId,processTriggerNav/rcmCandidateId
Authorization: Basic {{$dotenv sf_api_auth_base64}}
Accept: application/json